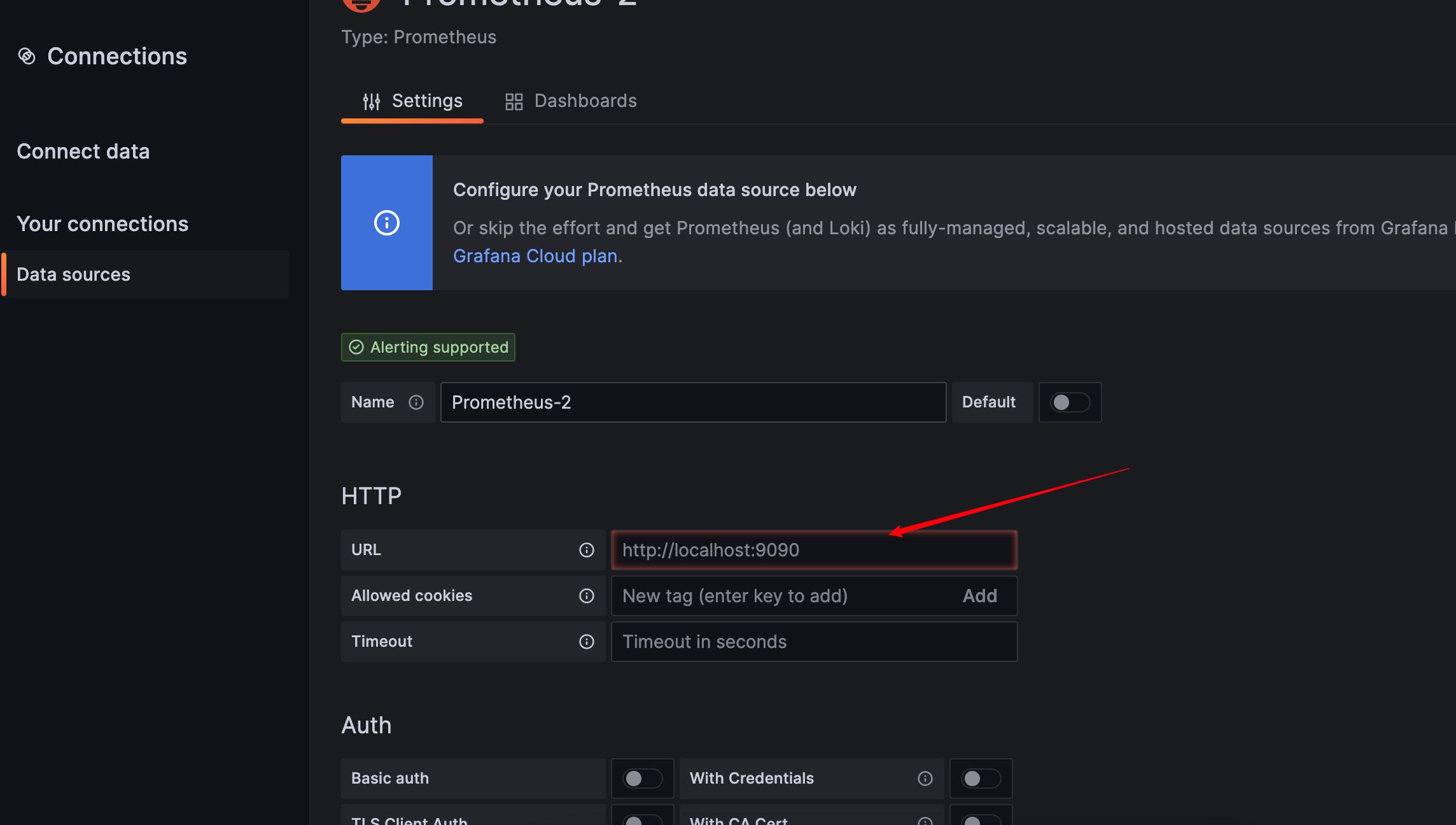
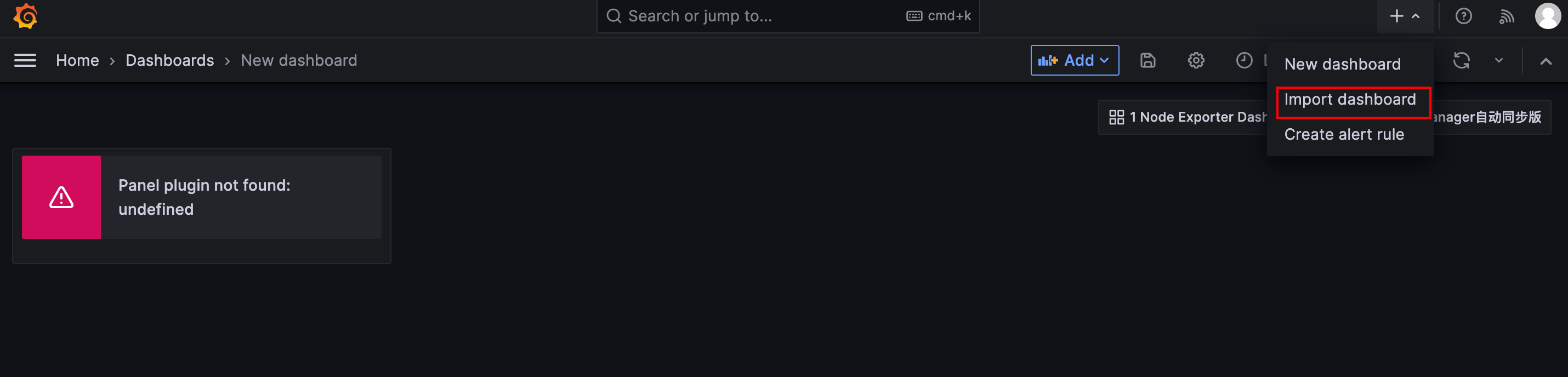
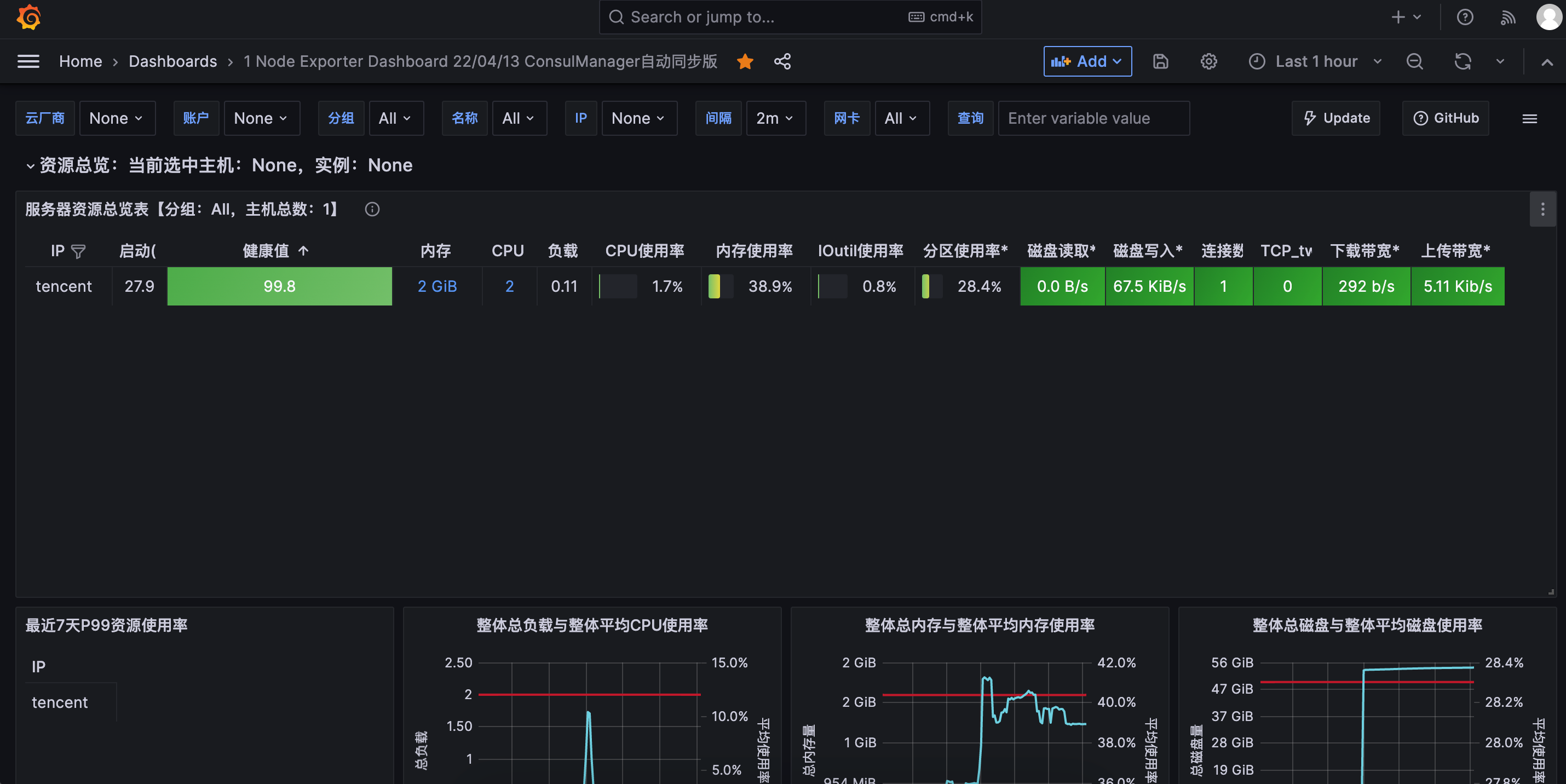
服务器消息块(Server Message Block,缩写为 SMB),又称网络文件共享系统(Common Internet File System,缩写为 CIFS, /ˈsɪfs/),一种应用层网络传输协议,由微软开发,主要功能是使网络上的机器能够共享计算机文件、打印机、串行端口和通讯等资源。它也提供经认证的进程间通信机能。它主要用在装有 Microsoft Windows 的机器上,在这样的机器上被称为 Microsoft Windows Network。
经过 Unix 服务器厂商重新开发后,它可以用于连接 Unix 服务器和 Windows 客户机,执行打印和文件共享等任务。
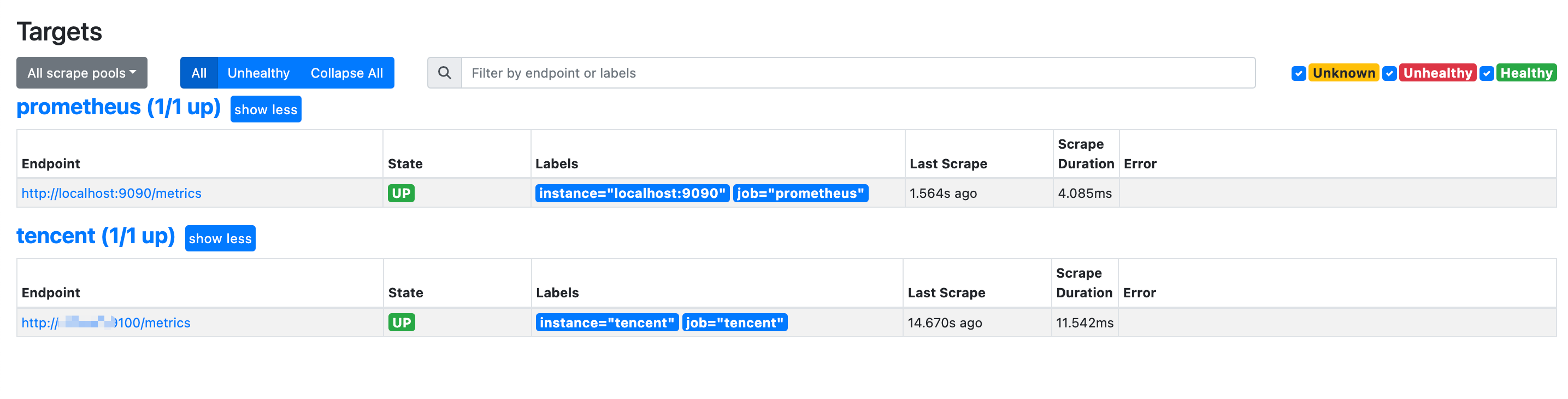
global: scrape_interval:15s# Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval:15s# Evaluate rules every 15 seconds. The default is every 1 minute.





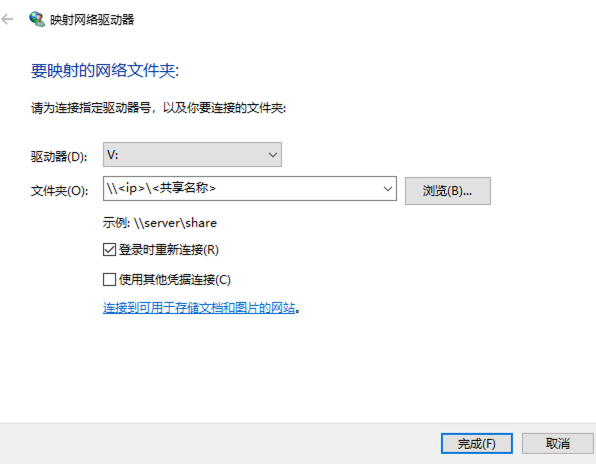
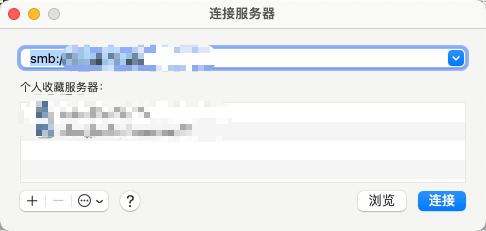

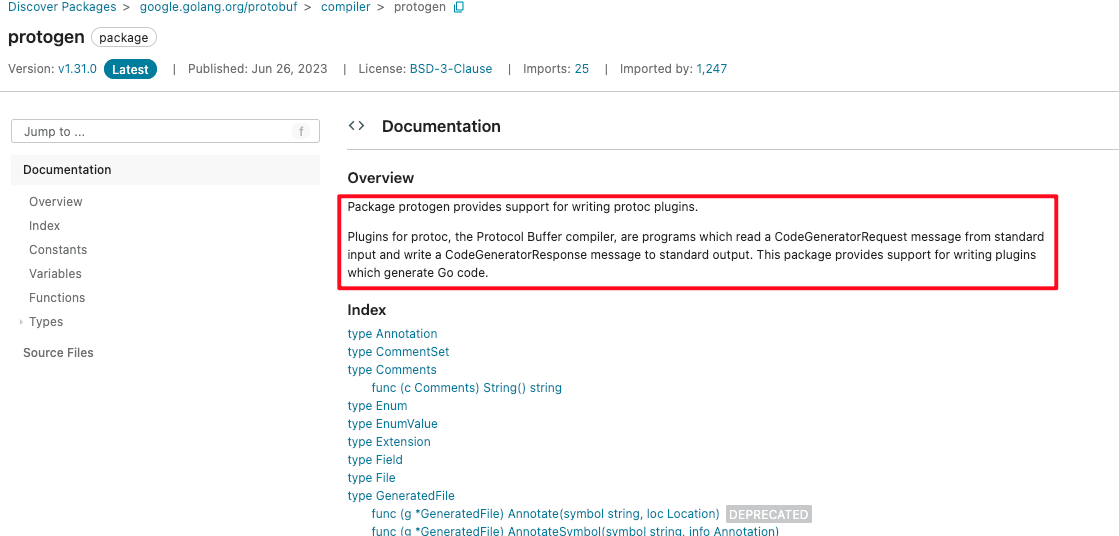
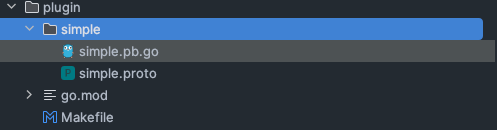
 今天我们就一起来实现一个插件吧!
今天我们就一起来实现一个插件吧!